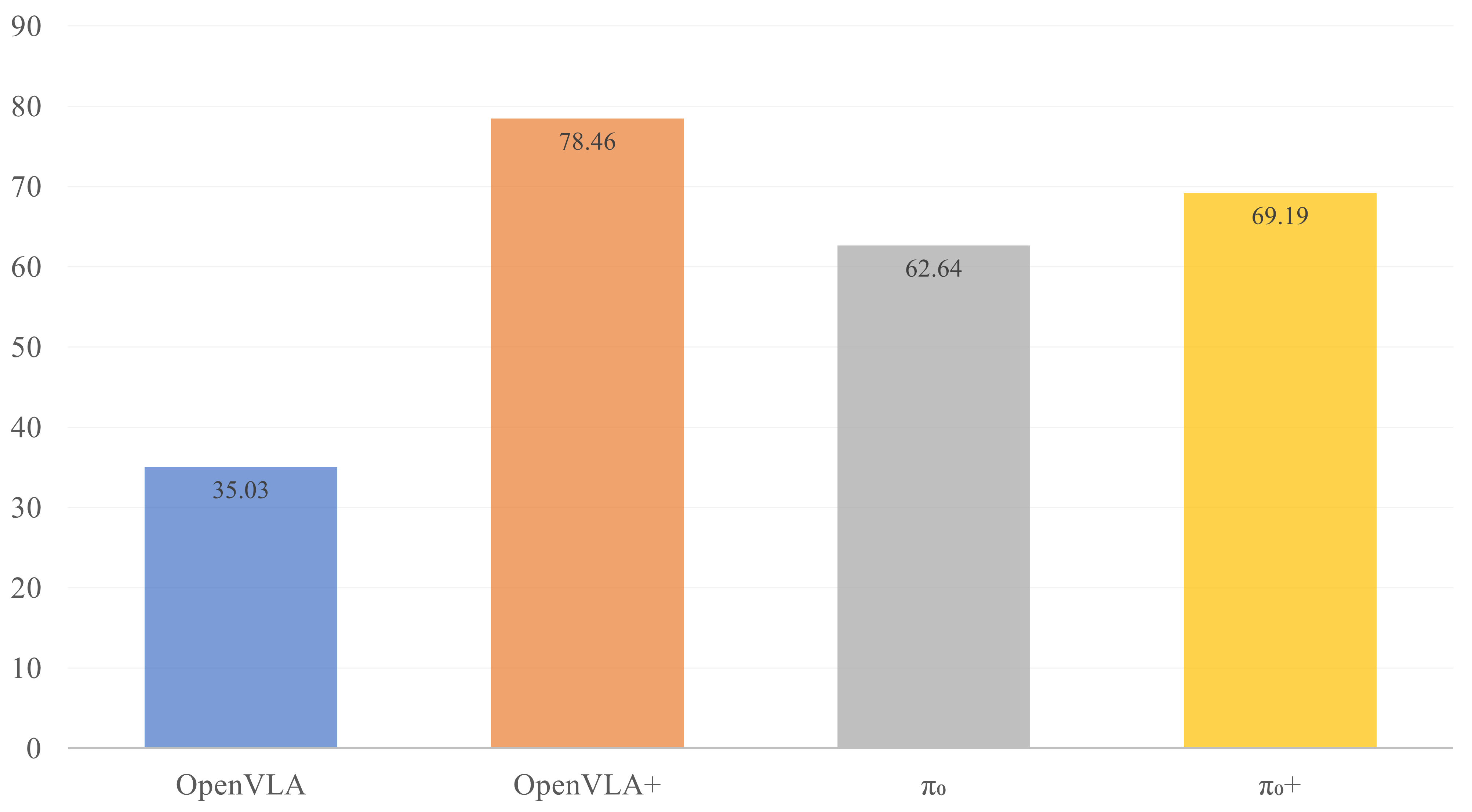
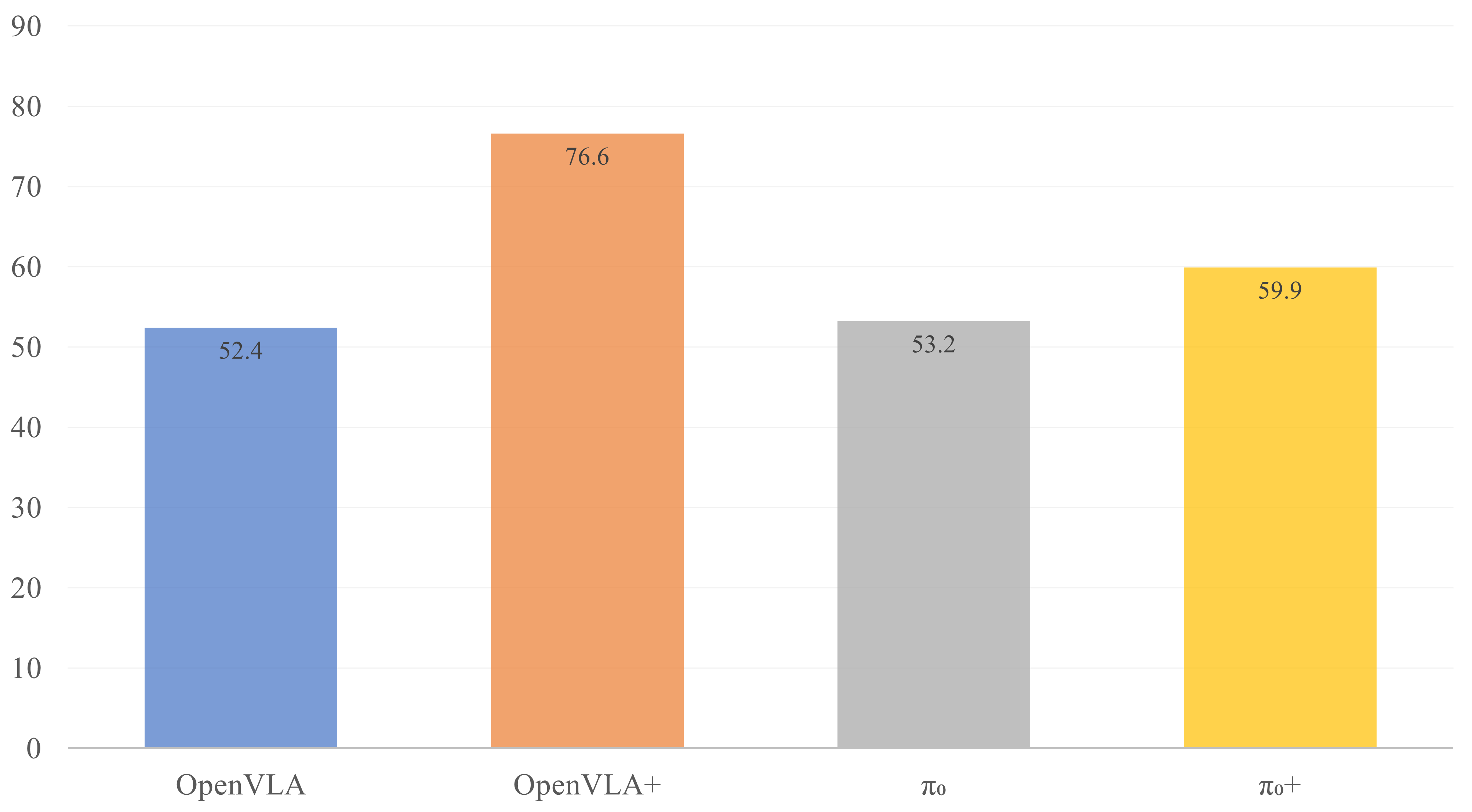
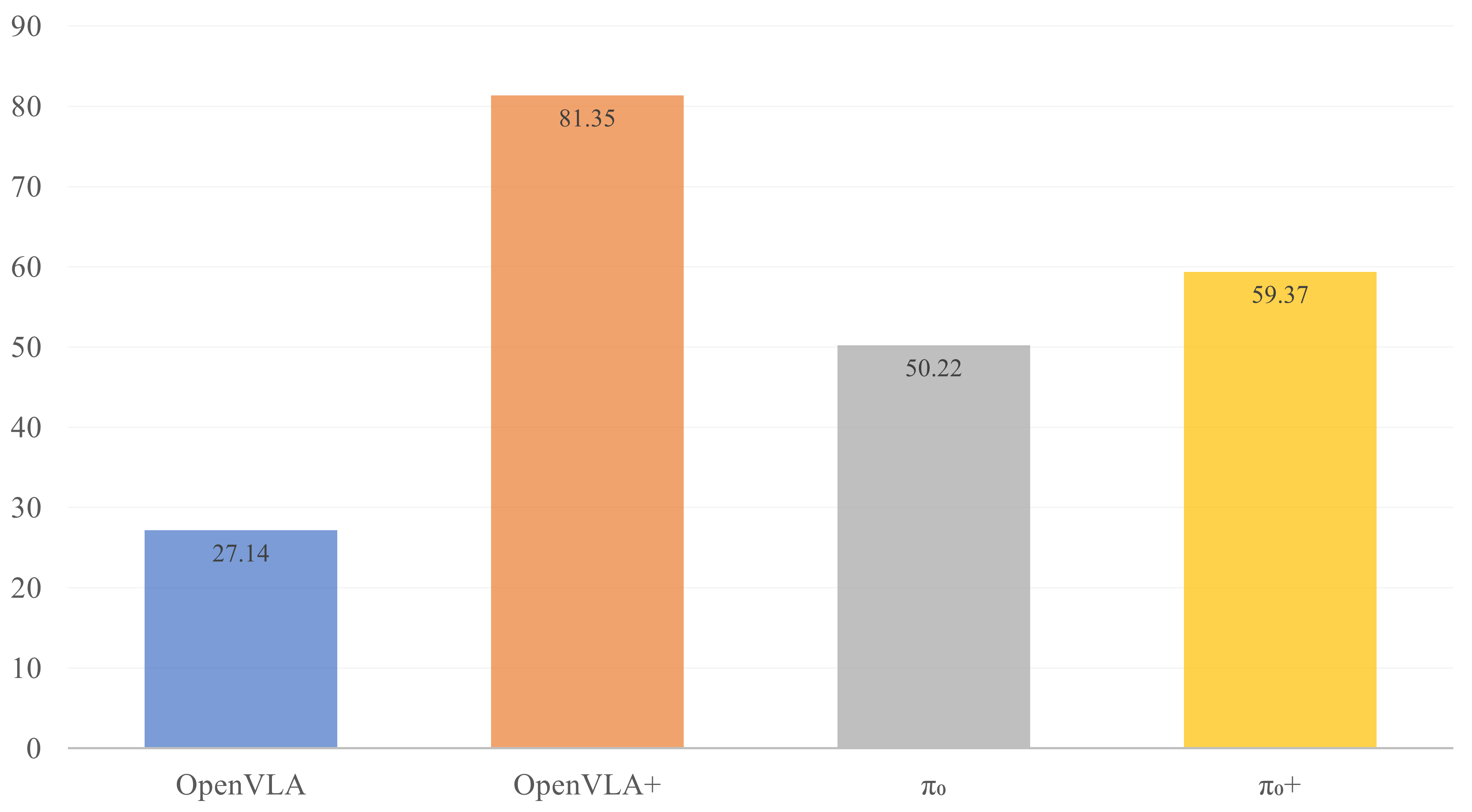
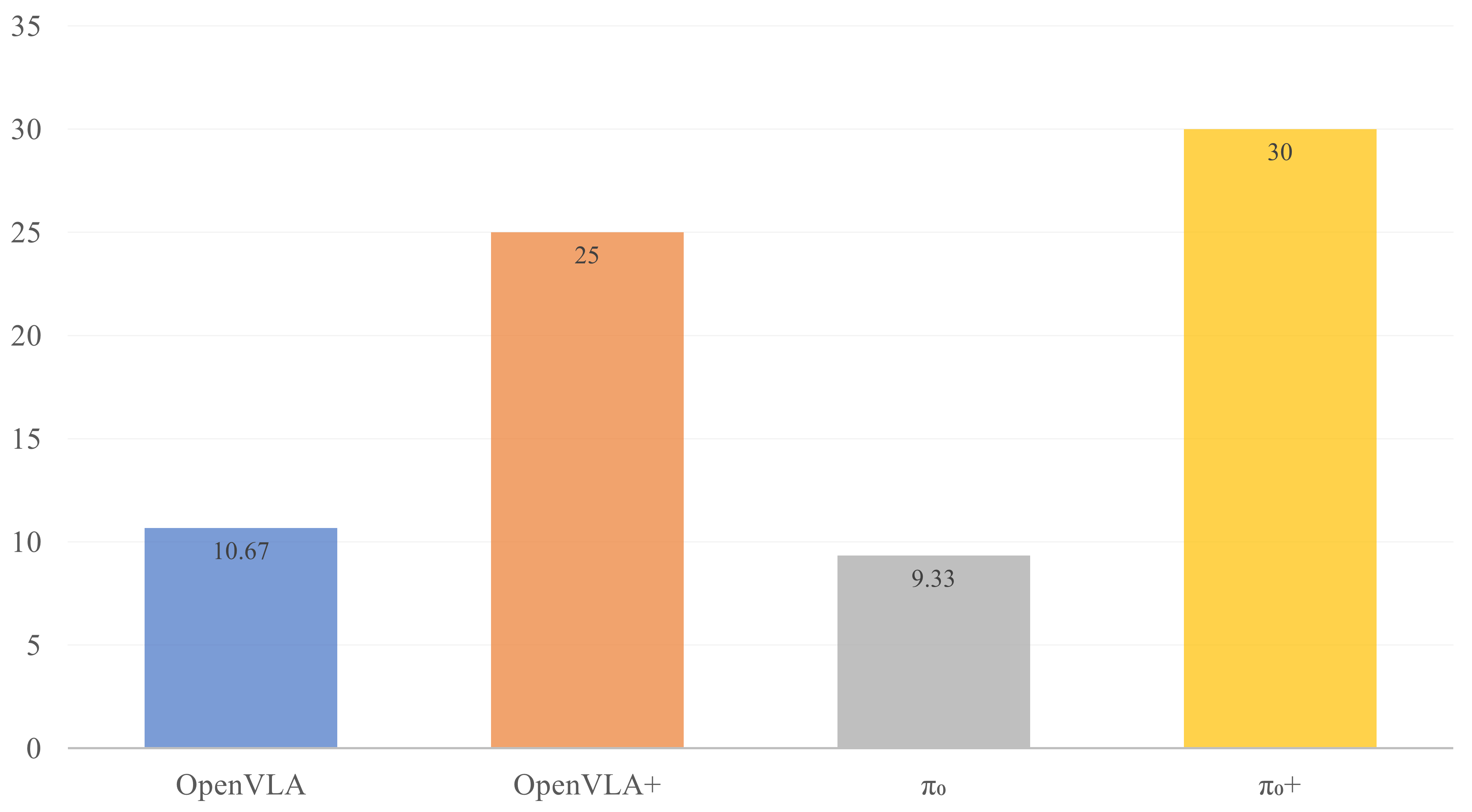
Method
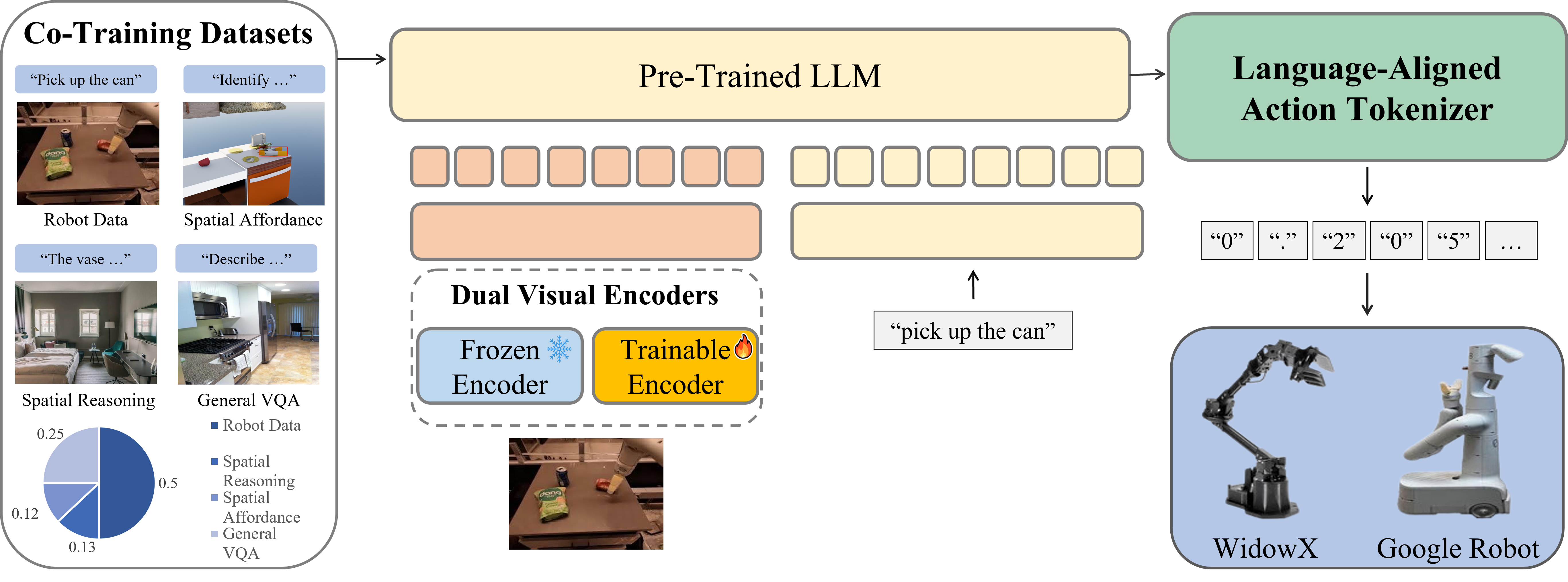
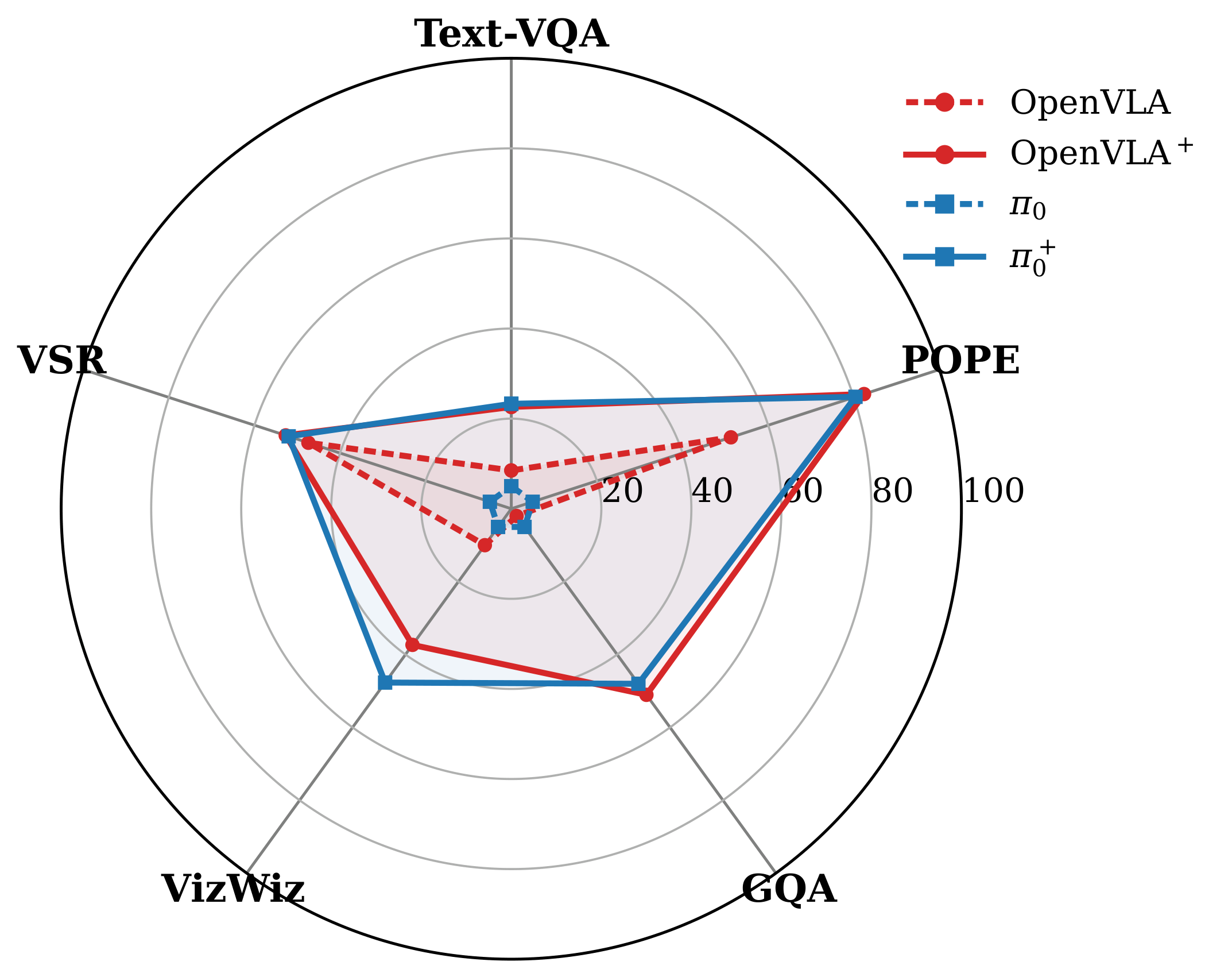
Our framework is built on three key ideas to prevent representation degradation. (1) Partially-Frozen Visual Encoders: We use two encoders—one frozen to preserve robust, pretrained VLM features and one trainable to adapt to the specific robot task. (2) String-Based Action Tokenizer: We represent continuous robot actions as strings, unifying them with the text-based pretraining of the language model. (3) Co-Training Strategy: We mix robot demonstration data with vision-language datasets that emphasize spatial reasoning, preventing the model from overfitting to robot-specific data and enhancing its generalization capabilities.